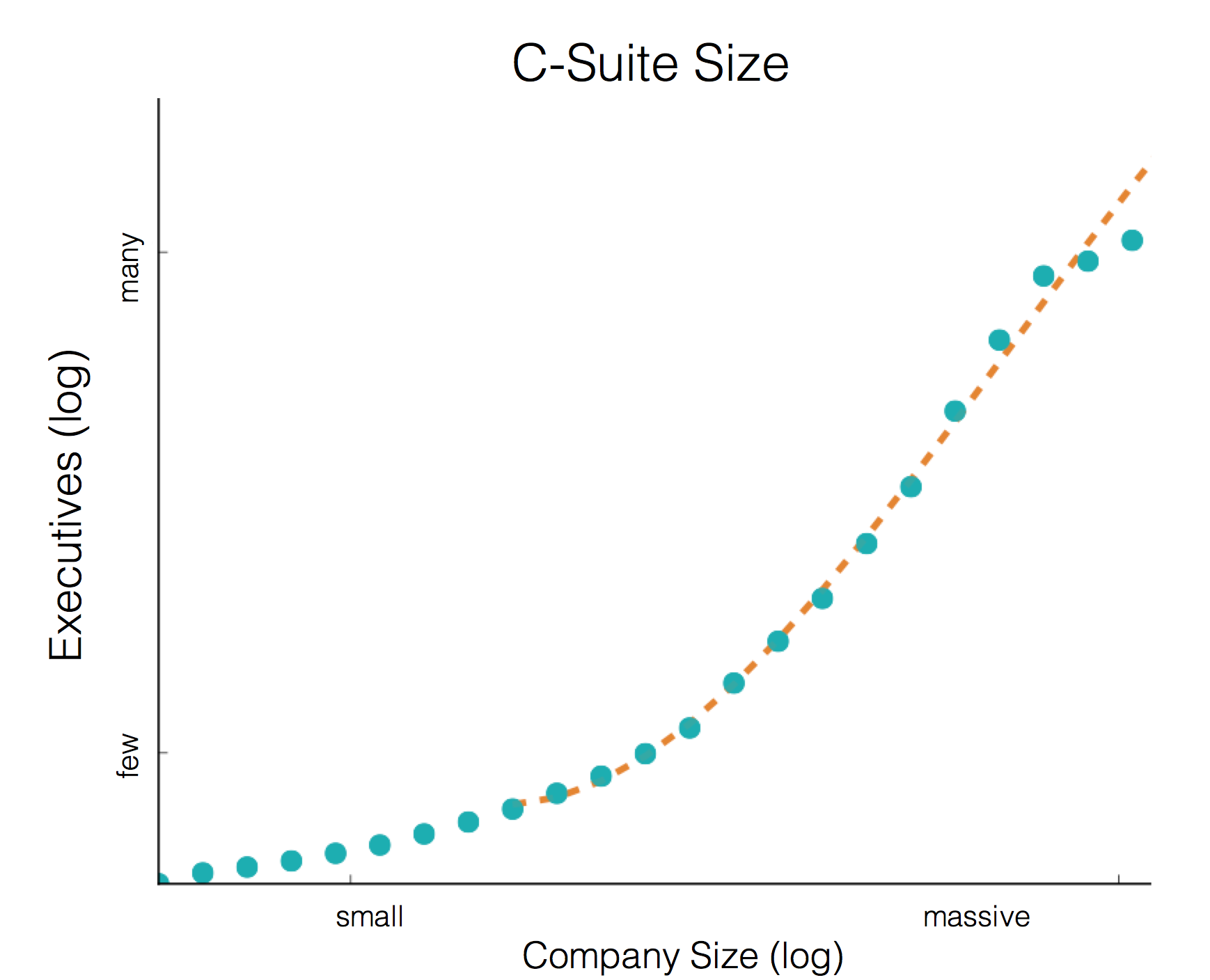
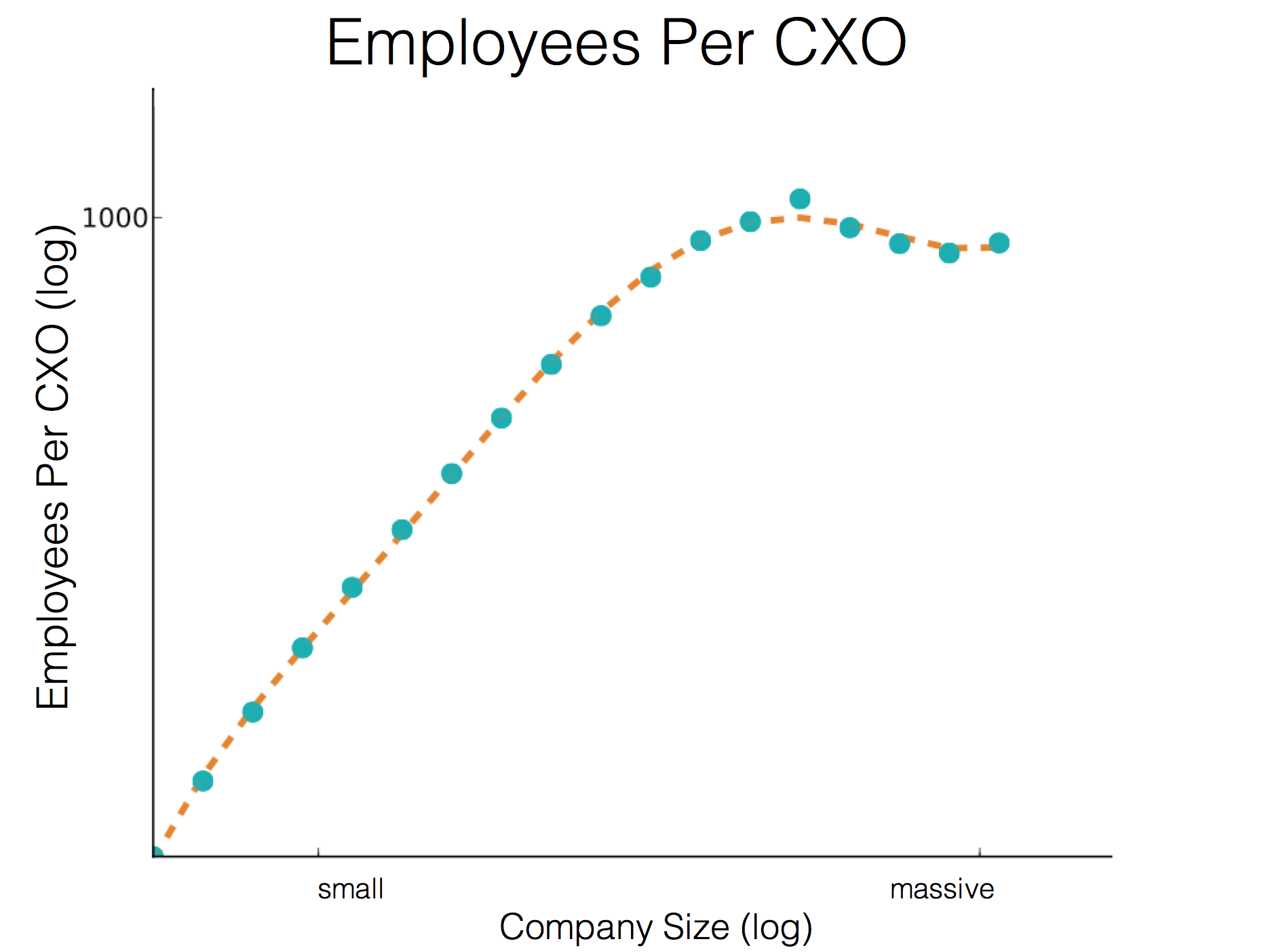
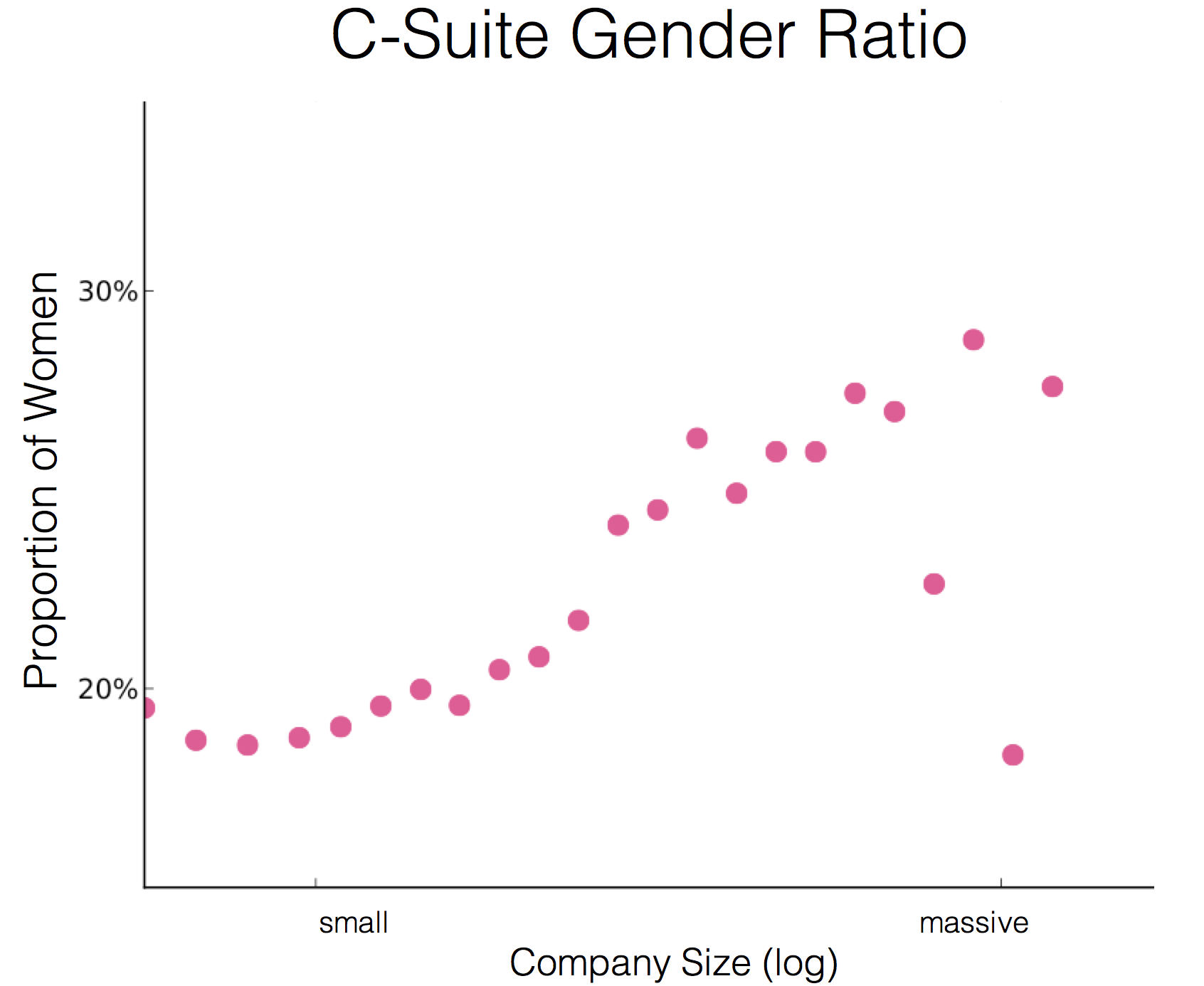
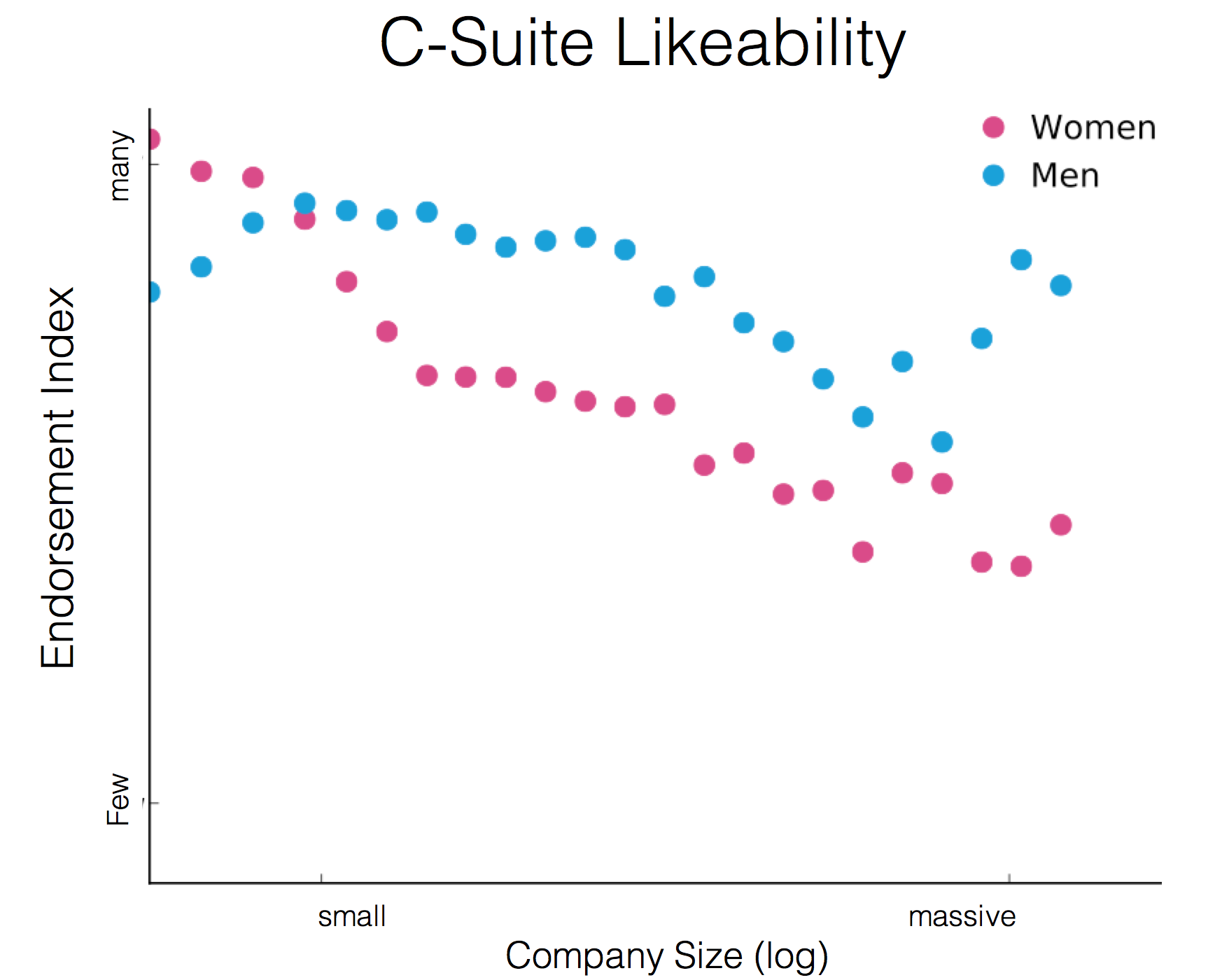
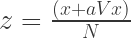Many great fields have principles that set the direction and bounds of the field. The feature-bug of data science is that it can borrow from a nearly universal set of fields, but with that it must also adhere to a nearly universal set of principles. Here are the principles I’ve adapted from other fields and applied to my data science work over the years. The reason I think they’re worth sharing is, these principles have become second nature to guiding my work. Some I’ve been using for 7 years, which is an incredible shelf life in data science, and possibly a good indicator of continuing to be useful.

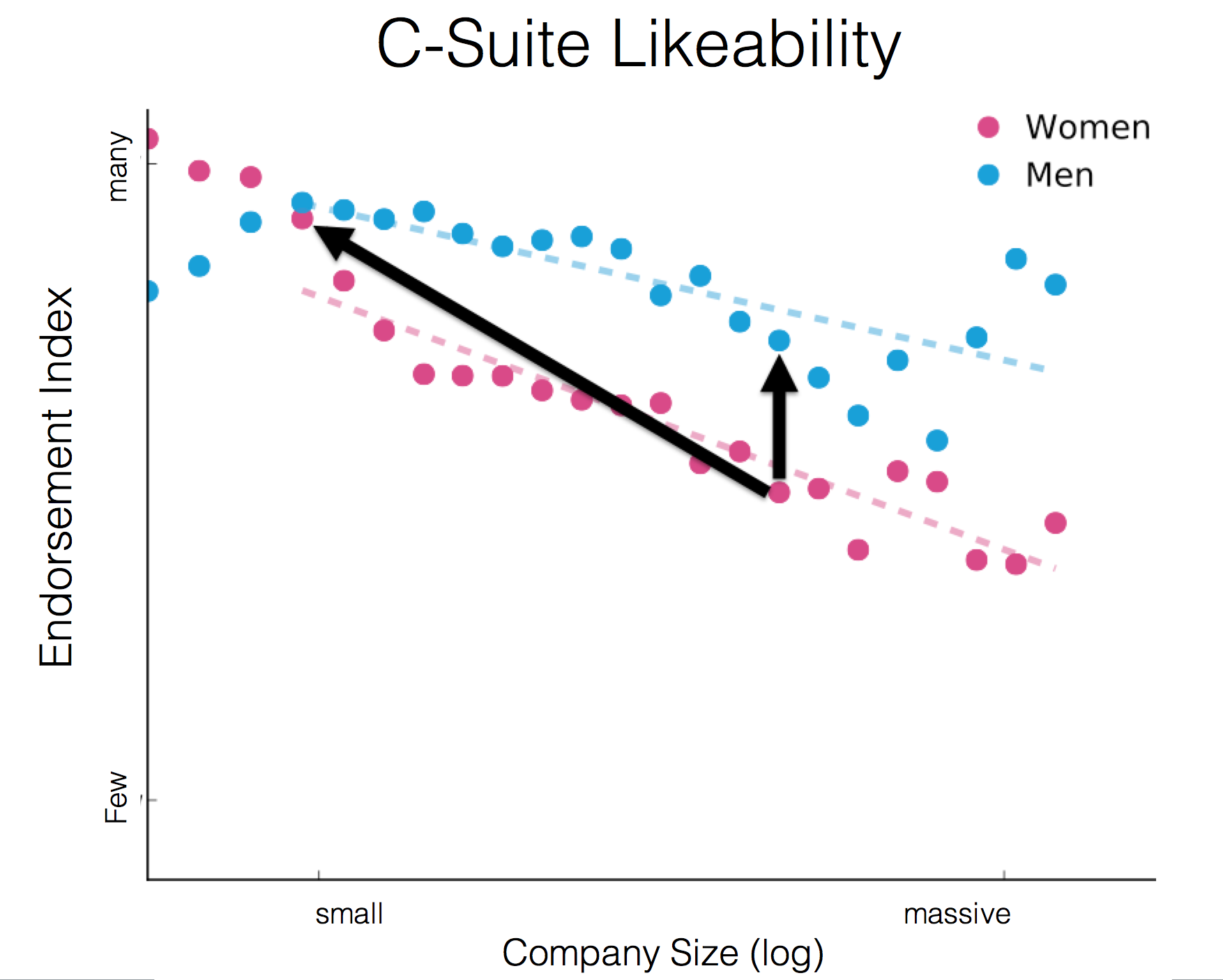
(Astronomy) In the Universe, the Earth is not unique, and neither am I. This is modified from astronomy, where the rule of thumb is if you do an analysis or simulation of the universe that results in the Earth being in the center of the solar system, the center of the big bang, or being unique in any other way – then your analysis is wrong and promptly thrown out. At least that’s how I remember it from @profjsb‘s astronomy class. I can’t count the number of times, the humility required to adhere to this principle has allowed me to see what the data is trying to say. It is at fundamental odds with how much analysis is approached, commonly by product centric folks. The start is “my experience with the product is this, let’s measure how many people had a similar experience. If that’s enough folks, then let’s build an experience I would like.” If we rule out that our personal experiences are the epicenter of how millions of people experience the world, then we can take a step back start with “what is the experience people are having with the product? Which experiences need to be improved? How can we improve them?“
(Law) To tell the truth, the whole truth, and nothing but the truth. I haven’t met may data scientists who would need an explanation of this one. Every company I’ve worked in has tried to change the format of results being presented from “Increasing button size, makes the call to action more apparent, and lifts conversions” to “Increasing button size to a maximum of 80x30px, corresponds to a [2.9%, 3.2%] lift in conversions over button sizes 25% smaller.” Data scientists would love to tell the truth, the whole truth and nothing but the truth – but the truth is often hard to parse and re-communicate. So we compromise on this principle. For the whole truth, confidence numbers are dropped. For nothing but the truth, data scientists are asked to speculate. Someone once asked me to speculate too often, so I handed them a Magic 8 ball. They were not impressed, but the outcome was the same, and it cost me far less time. The ask here is not for data scientists to adhere to this one, the ask is for folks working with data scientists to ask us to adhere to this one.
(Medicine) First do no harm. This is the Black Lotus of principles, rarely used and unforgettable when it is. Data science is a hard to understand and unpredictable new tool that is being integrated into robust, battle tested, well thought through, business processes and world sustaining systems, ie executive decision making, airplanes and judicial decisions. How data science is added to these systems should be in a first do no harm manner. These systems work, they could be improved, but they should not be destroyed or put into analysis paralysis.
(Military) The data is neutral. I can’t believe it, The Jungle is Neutral, only has 33 reviews on Amazon. That book influenced how wars were fought. I learned this principle through my family’s military ties. It’s a good perspective to ground yourself in when tackling a new dataset or data infrastructure. The high level idea is your surroundings are neutral, they are not going to jump up and help you out, nor are they going to discriminately attack you. The template is then to respect the data as an independent entity, understand its behaviors, and work with it as best you can, respecting its limits. If you don’t, you’ll get bitten.
(Super Heroes) With Great Power Comes Great Responsibility. Personally, I don’t think there has ever been a field created over night with such power encapsulated in the average practitioner. Data scientists are influencing the experiences of millions of people at a time. An artist selling a million albums is considered going Platinum. If data scientists started putting Platinum Albums on our walls every time we influenced a million people, we’d need platinum wall paper. Data scientists have great power. For the philosophical reasoning of how this great power can lead to the most villainous of behavior I defer to Josh Wills. Wielding this power should be coupled with the responsibility of knowing what we’re doing and being prepared to account for how we use our power, as we use it.
Thanks for the read! I’m all ears on what principles folks think should be added or how these should be applied in different situations.
Additional principles to consider adapting in the future:
- (Military) No plan survives contact with the enemy. For complex analysis, it’s hard to know what is going to be involved beforehand. The best approach is to look at the data and adapt.
- (Physics) For every action, there is an equal and opposite reaction. While we may love isolated independent experiments, that’s rarely how things work, and we should look for and find the reactions.