
| Cohort | Actual Performance | Observed Performance |
|---|---|---|
| A | x | z |
| B | a · x | c · z |
By assuming all interference is across cohorts, we can bound the actual experimental impact a. The relation between observed to the actual performance is then:
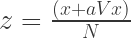

With a small bit of algebra we find a beautiful bound:

So, why is it gorgeous? Let us consider the extrema.
- In the ideal experiment V = 0 and the bound is a = c. Nice! Our bound is tight.
- When all activity in cohort B is a byproduct of cohort A, c = V and the bound is a = 0. So in a dangerous system, a becomes scary.
In general the bound remains tight for low values of V and explodes with increasing social influence. 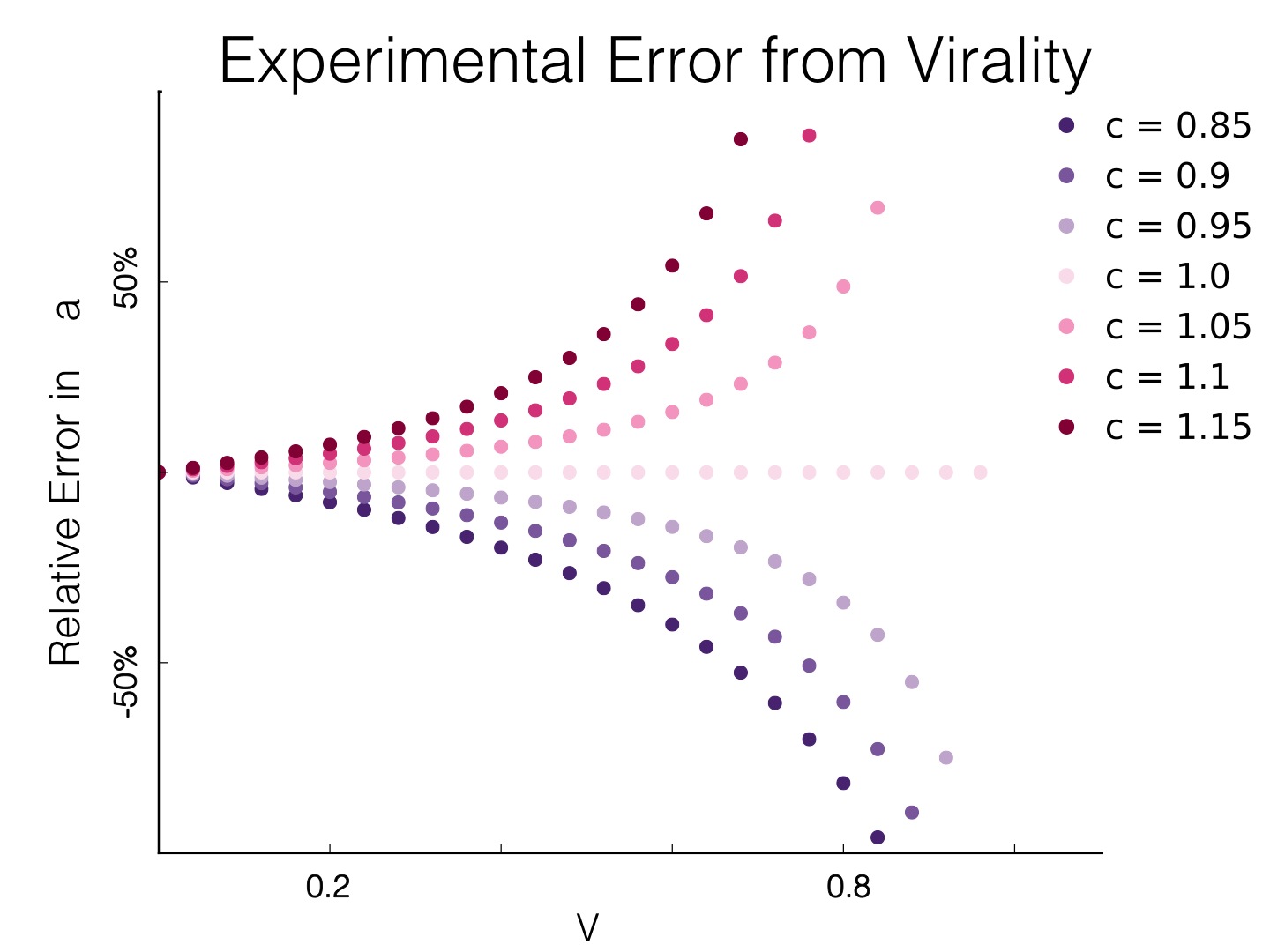 In social networks, there are hundreds of features with V > 0. Fortunately, it’s easy to bound how much virality is impacting your results. If the impact is larger than a tolerable amount of error, then time to bring out the sledge hammer and split up your network. If it’s a tolerable amount of error, then march forward and conquer with your traditional a/b framework! When in doubt. Gold:
In social networks, there are hundreds of features with V > 0. Fortunately, it’s easy to bound how much virality is impacting your results. If the impact is larger than a tolerable amount of error, then time to bring out the sledge hammer and split up your network. If it’s a tolerable amount of error, then march forward and conquer with your traditional a/b framework! When in doubt. Gold:
. . . . Additional Examples with V = 0.04:
| Cohort | Actual Performance (T) | Observed Performance (T) | Actual Diff Bound |
|---|---|---|---|
| A | x | z | |
| B | a x | 0.97 · z | [-3.2%, -3%] |
| B’ | a’ x | 1.03 · z | [+3%, +3.3%] |

