For search algorithms, Mean Average Precision(MAP) and its variants rule the roost of metrics on search dashboards. MAP is also one of the most stubborn metrics with which I’ve ever worked. I’ve seen dramatic algorithmic improvements launch themselves into the +0% impact on MAP experiment graveyard. …………but does MAP measure what we think it does?
Search quality or information retrieval is built on two cornerstones, give me everything I want and give me only what I want. It is easy to measure these aspects of search quality with Recall (proportion of everything that is recovered) and Precision (proportion of good stuff returned.)
Ideally we could have perfect Recall and perfect Precision. In the absence of perfection, it’s nice to know how close we can get. Then we can run experiments and march towards an optimal search algorithm. Enter Mean Average Precision (MAP). MAP combines Recall and Precision into one number. If MAP is 1, you have achieved perfection. If MAP is 0, delete your search algorithm and consult Stack Overflow. Let us take a look at what MAP means when it is somewhere between 0 and 1.
To visualize a metric, let me rustle up a skeleton in the math knowledge closet. Contour curves, level sets, elevation maps, and topography maps are all the same thing. In short, they are visualizations where any two points connected by a curve have an equal value. For jogging the memory here is an elevation map of Halcott Mountain. Any two lat/long coordinates connected by a red line are at the same height above sea level. The red dots outline a path from the base of the mountain to the top. The more rapidly a hiker crosses red lines, the steeper the trail.
 Now it’s plug and chug time! We can do the same for MAP. Let us say latitude now represents Precision and longitude represents Recall. Any two lat/long or Precision/Recall points connected by a line have the same height or MAP score (green lines represent better MAP scores than red lines).
Now it’s plug and chug time! We can do the same for MAP. Let us say latitude now represents Precision and longitude represents Recall. Any two lat/long or Precision/Recall points connected by a line have the same height or MAP score (green lines represent better MAP scores than red lines).

Gorgeous! What does it mean?
For most search algorithms, they will have a MAP score that puts them on the most curvy of the lines, either with Precision < 0.3 or Recall < 0.3. Search is a hard problem. To go back to the mountain analogy, if you want to ski down the mountain as quickly as possible you want to change elevation as quickly as possible, in other words cross contour lines as quickly as possible.
Let us consider a common set of values:
- Precision > 0.3 (~clicks occur on the first 3 results)
- Recall < 0.5 (~1 in 2 searches results in a click)
then
- For some values a 1% improvement in Recall is the equivalent of a >150% improvement in Precision!
For a visualization consider the three points marked in the figure. If an experiment improves Recall, it will have half the impact on MAP at point b as it does at point a, and a fourth of the impact at point c as it does at point a.
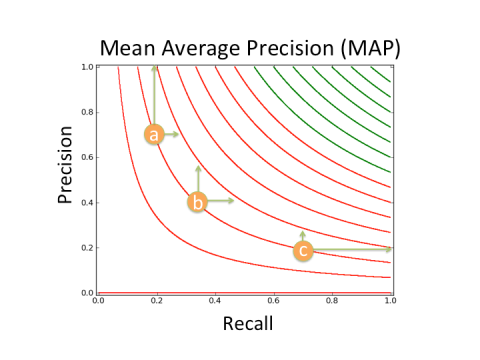
Points a,b, and c all have the same MAP value. Vertical green arrows are how much Precision would have to increase to have the same affect as the increase in Recall marked by the horizontal arrows. The shorter the arrow the easier to achieve. The long arrows are particularly hard to achieve.
That’s nice. Why does it matter?
It means MAP is not measuring what we think it does! In regions common for search algorithms to score, good changes in Mean Average Precision, MAP, are from either changes in Recall or Precision, but not both! In short, a search team seeking to improve MAP may waste resources on experiments with good returns in Precision, miniscule returns in Recall, and consequentially no returns in MAP.
Footnote: a similar exercise can be used to show that Discounted Cumulative Gain (DCG) and other MAP variants inherit these characteristics as well.



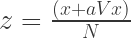


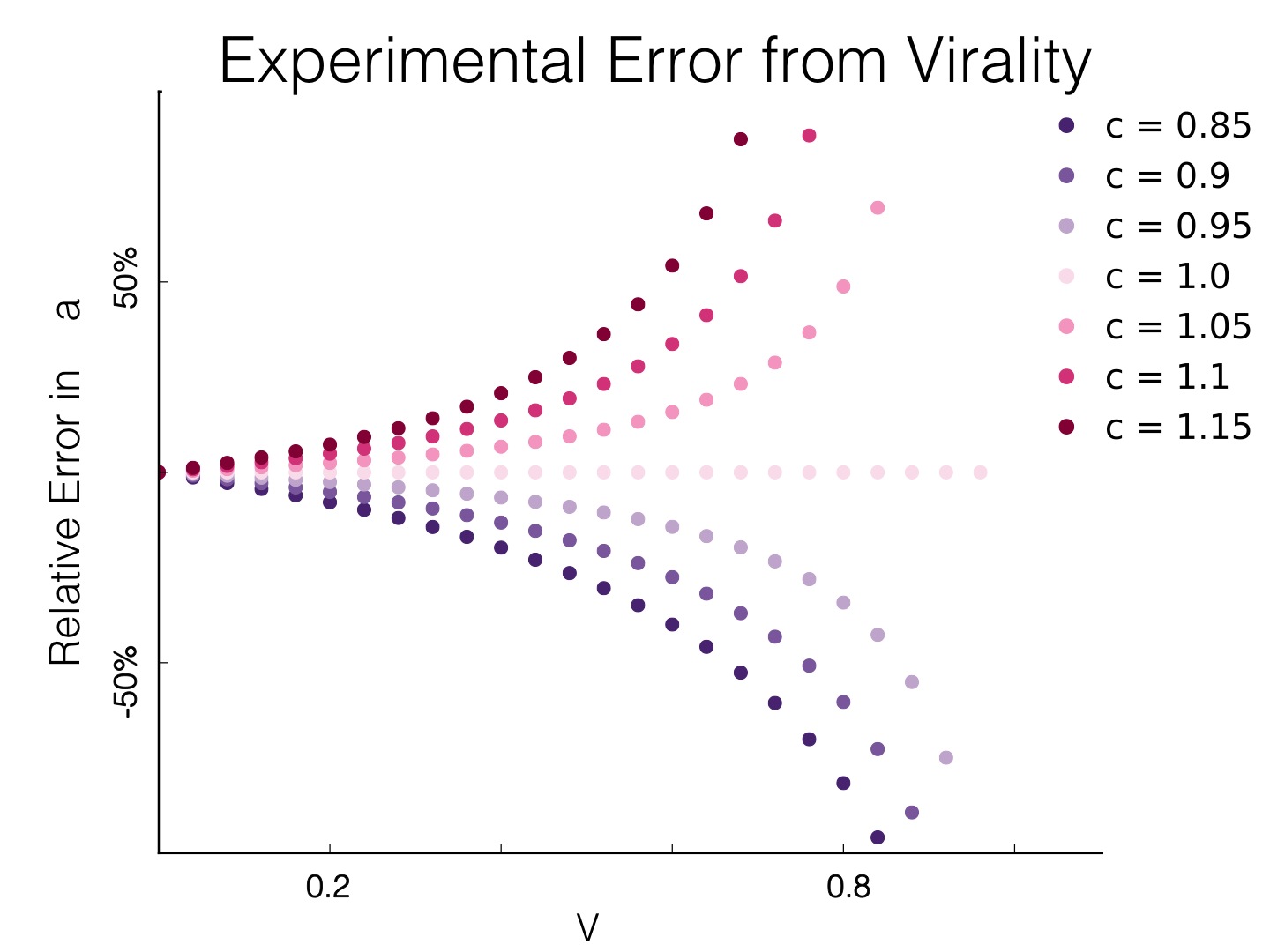 In social networks, there are hundreds of features with V > 0. Fortunately, it’s easy to bound how much virality is impacting your results. If the impact is larger than a tolerable amount of error, then time to bring out the sledge hammer and split up your network. If it’s a tolerable amount of error, then march forward and conquer with your traditional a/b framework! When in doubt. Gold:
In social networks, there are hundreds of features with V > 0. Fortunately, it’s easy to bound how much virality is impacting your results. If the impact is larger than a tolerable amount of error, then time to bring out the sledge hammer and split up your network. If it’s a tolerable amount of error, then march forward and conquer with your traditional a/b framework! When in doubt. Gold:

 to
to  algorithms is phenomenal! And, javascript libraries have started tapping into
algorithms is phenomenal! And, javascript libraries have started tapping into 


 . Use correlation coefficients between sends and reads for long term user engagement to chose
. Use correlation coefficients between sends and reads for long term user engagement to chose  . This approach can rapidly get away from you as your app or site increases in complexity.
. This approach can rapidly get away from you as your app or site increases in complexity.
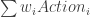 , a weighted sum over the actions users can take.
, a weighted sum over the actions users can take.


