A perfect storm has been brewing and enabling my passion for rapid data prototyping. Clusters have grown to handle a year+ of data in minutes to hours. Company’s investments in ETL pipelines make big data small – going from feasible 
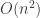
 That is a hard won success rate. Data prototypes are particularly vulnerable to early dismissal compared to product, infrastructure, or design prototypes. When surveying results it is easy to imagine if the elements of a page were better aligned or if the infrastructure ran on more machines. For data products, it’s hard to imagine if search results were added that are not on the page. It’s hard to imagine data that is not there.
That is a hard won success rate. Data prototypes are particularly vulnerable to early dismissal compared to product, infrastructure, or design prototypes. When surveying results it is easy to imagine if the elements of a page were better aligned or if the infrastructure ran on more machines. For data products, it’s hard to imagine if search results were added that are not on the page. It’s hard to imagine data that is not there.
Here are the recommendations I sweat blood to learn. Many of these recommendations may seem small, but details are vital. You will be amazed at how practice and experience change your interpretation of them over time. To set your data product up for success, without further ado:
Days before Hackathon:
- Sketch all the components before you begin and fit components to people
- Pre-generate and store the baseline data set required for your product to work. This is key as online data generation will frequently fail for prototypes and hamstring your demo. By limiting your demo to employees, you can precompute and store data in a temp database to mimic real time computation.
- Sanity Check the data density and quality for special users, such as your team and ceo
- Use basic metric checks to check data quality
- Have a default data set that loads in the event of a database or data error. This will let you showcase front end work in the event of an error.
- Personalize! You have a baseline data set and algorithm, setting parameters such as font size, category preference, on a per user basis will take your product to the next level.
- White list for employees and people who will be at the demo day. Make sure it is a recent list of employee ids.
- Plan on the Hadoop clusters being overwhelmed during the hackathon, particularly for summer hackathons with interns
- Model – keep it simple – complex models require tuning and large amounts of training data
Day of Hackathon:
- Set your prototype up so that a reboot requires one command and takes less than five minutes
- Do not randomize! It can be tempting for team members to try and make an algorithm look smarter than it is by faking it. When it succeeds you can not say why and when it fails it really fails.
- Visualize the data in a novel and productive manner; demos of weights in a model don’t impress
- Spring board – use platforms available internally – hosting, id verification, etc
- Mobilize – ideally set the demo up on loaner phones; at least address how the product works on mobile
- Record user interactions. This can be done with simple http request tracking or by adding url parameters like ‘&our_awesome_hack.’ I particularly like url parameters, as the interactions your product drives with the rest of the site are then stored with the company’s data and you have access to all of your daily tools to run follow up analysis.
- Organize – for teams of three or more sit in the order of dependencies from backend to frontend. This way api and blocker discussions are easily facilitated.
- Choose a central host server and set the permissions to be as accessible as possible. Double check the host has reliable connections, exceeds memory and processing requirements, has all necessary installed packages, and is not running any other processes.
- Six packs of Black Butte Porter and Martinelli’s. A successful data hackathon has all data generated in advance. If you are the data person, take on the role of Scrum Master. Handle all unexpected tasks, research special requests, and organize stress relief breaks for the team.
- Details, details, details. Use every last minute to refine css, html, adjust margins, and reduce load time. Each of these details should not affect rebooting the prototype within five minutes and should be tested after each change.
Days after Hackathon:
- Present how many people accessed your prototype, what their responses were, what you learned, and what is necessary for productionizing
- Reflect. Ask yourself the hard question. Should this product go to product or not.
While this may seem like a long list just for a hackathon – data product prototypes fail fast. Having results off for the one person responsible for sourcing, is equivalent to summoning the coroner.


 . Use correlation coefficients between sends and reads for long term user engagement to chose
. Use correlation coefficients between sends and reads for long term user engagement to chose  . This approach can rapidly get away from you as your app or site increases in complexity.
. This approach can rapidly get away from you as your app or site increases in complexity.
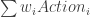 , a weighted sum over the actions users can take.
, a weighted sum over the actions users can take.

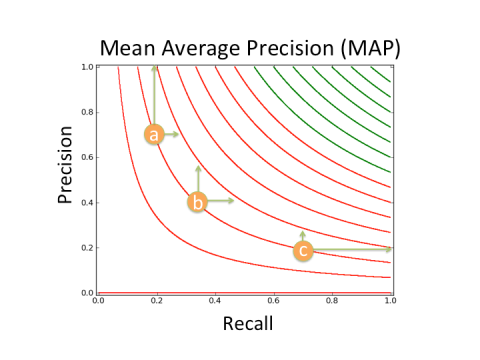
 Now it’s plug and chug time! We can do the same for MAP. Let us say latitude now represents Precision and longitude represents Recall. Any two lat/long or Precision/Recall points connected by a line have the same height or MAP score (green lines represent better MAP scores than red lines).
Now it’s plug and chug time! We can do the same for MAP. Let us say latitude now represents Precision and longitude represents Recall. Any two lat/long or Precision/Recall points connected by a line have the same height or MAP score (green lines represent better MAP scores than red lines).